
Hashing is one of the most frequently asked topics in the placement interview. It forms the backbone of many real-world applications, which makes this concept very important for every individual entering into the world of development. In this blog post by experts from data structure algorithm institute in Delhi, we will break down the topic and cover every single aspect of Hashing in detail.
What is Hashing in data structure?
Hashing is a process of converting an input of any length into a fixed-size string of text using a mathematical function. This means that, no matter how long the text is, it will be converted into an array of numbers and letters through an algorithm.
- The original data that is to be hashed is called input.
- The algorithm used to do so is called a hash function.
- The output is defined as the hash value.
While many formulas can be used to hash a message, a cryptographic hash function needs to possess certain qualities to be considered.
- Each hash value or output has to be unique. This means that it is impossible to produce same the hash value entering different inputs. Therefore, the same message will always produce the same hash value.
- The hashing speed is also an important factor. A hash function should be quick to produce a hash value.
- A hash function needs to be secure. It is extremely difficult to determine the input based on the hash value. The slightest change to an input should generate a hugely different hash.
What is the hash function?
A hash function is defined as a mathematical function that converts the arbitrary input size into a fixed-size output. The output generated is known as the hash value and hash code.
For example:
Input: "Hello"
Hash Value: 5d41402abc4b2a76b9719d911017c592 (MD5 hash example)Key rules of hash functions
- It must be deterministic: The same input always produces the same output
- Fixed length output for all possible inputs.
- The output must be Irreversible outputs.
Applications of Hash Functions
- Hash Tables: used in data structures for faster data retrieval like hash maps.
- Password security: it stores hashed passwords instead of plain texts.
- Fast searching: it is used to speed up the searching and indexing mechanism in databases.
Example of custom Hash Function in Java
public int customHash(String key) {
int hash = 0;
for (int i = 0; i < key.length(); i++) {
hash += key.charAt(i);
}
return hash % 10;
}Hash Tables in Data Structures
A hash table is defined as a data structure that organises and store data in the form of key-value pairs. It allows us to perform faster operations on data such as retrieval, deletion, and insertion of data. In a hash table, keys are commonly accessed using a special function called hash function. This function will convert the keys into an index to store or fetch the respective value.
- Null keys cannot be stored in a hash table.
- Values can be null and multiple null values can be stored in the hash table.
- Hash tables provide constant time complexity that is O(1) for various operations such as insertion, deletion, and search operations.
Here, we will see an example of how a hash function works while creating indexes from a key.
Key: "John"
Hash Function: ASCII sum of characters % 10
"John" -> (74 + 111 + 104 + 110) = 399 % 10 = 9This is how “John” will be stored at index 9 in the hash table.
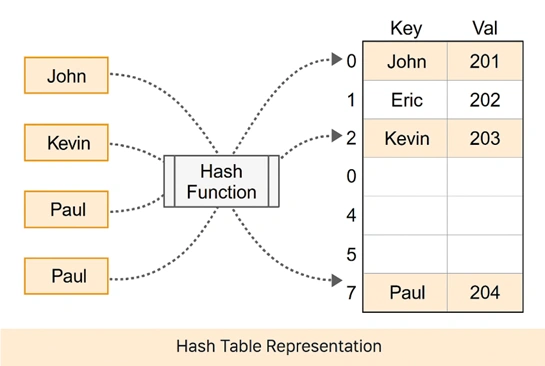
Collision in Hashing
In hashing, each key is passed through a hash function to generate a specific index in the hash table, where it will store its respective value. However, sometimes two different keys produce the same index. This situation is commonly referred to as collision.
For example:
- “name” → hash function → mapped at index 2
- “email” → hash function → mapped at index 2
Collision is a common issue in hashing which is handled using various techniques, which we will discuss now.
Collision Handling Techniques
In hashing, there are mainly 2 popular techniques used for collision handling:
- Chaining:
In chaining, each index in the hash table is associated with linked list. If multiple elements are hashed to the same index number, then all the elements will be stored on the linked list of that particular index.
For example:
We have a hash function: key % 5, and we want to insert some keys: [1, 6, 11].
- 1 % 5 = 1 → store 1 at index 1
- 6 % 5 = 1 → collision at index 1 → add 6 to the linked list at index 1
- 11 % 5 = 1 → another collision → add 11 to the same list
Disadvantages of Chaining technique:
- It needs extra memory for linked list.
- In this case, Access time may become slow because of greater chain length.
- Open Addressing:
In open addressing, if collision takes place, we search for another empty slot in the array using multiple strategies such as Linear probing, Quadratic probing, and Double Hashing. All the elements will be directly stored in the hash table, not in the linked list.
Example using Linear Probing:
Keys: [27, 18, 29, 28], Hash function: key % 10.
Now, we will perform as shown below:
| Key | Hash Function (key % 10) | Index in Hash Table |
| 27 | 27 % 10 = 7 | 7 |
| 18 | 18 % 10 = 8 | 8 |
| 29 | 29 % 10 = 9 | 9 |
| 28 | 28 % 10 = 8 (collision) | ( After probing) |
As, we noticed the collision at index 8, using linear probing we will check out the next index i.e. 9.If 9th index is also occupied, we wrap around to the beginning of the array.
- Try index 9 → occupied
- Try index 0 → empty → store 28 at index 0.
Disadvantages of Chaining technique
- Probing logic is more complex.
- It directly affects performance with increasing load factor.
Why collision occurs?
- Limited size of Hash Table:
When we try to store a greater number of elements in the hash table, due to its fixed size, some elements may get the same index which causes a collision.
- Poor Hash Function:
A poor or inefficient hash function may generate the same hash value for different keys, which causes the mapping of multiple keys to the same index.
- High Load Factor:
As the number of key-value pairs in the hash table increases, the chances of collisions also increase, because of the increased competition for limited index positions.
Types of Hashing in Data Structures
A Hashing function is used to map data to a fixed size hash table. Different hashing functions are used to convert keys into hash value. Some of the major mashing methods are:
- Division Method: In this method, the key is divided by the size of the table and the remainder will be taken as hash value.
- This is the simplest and fastest method.
- It is a good choice, if the table size is a prime number.
Formula: hash = key % tableSize
- Multiplication Method: Here, the key is multiplied by a constant(A) between 0 and 1. The fractional part of this result will be multiplied with the table size and the floor value of this will be taken as hash value.
- Floor function: Floor means rounding off the number to the nearest whole integer.
- This method is independent of table size.
Formula: hash = floor(tableSize * (key * A % 1))
- Mid-Square Method: While performing this method, we first square the key, extract the middle digits of the squared number and use them as a hash value.
For Example:
Key=12, Square=144, Middle Digits = 4, hash value =4.
- Folding Method: This method, breaks the key into two equal parts and add those parts together. The sum obtained or part of it is used as the hash value.
For Example:
Key = 123456; Two parts: 123 & 456; Add: 579; Hash will be 579
Rehashing and Load Factor
What is load factor?
It is defined as the measure that indicates how much of the hash table is currently occupied. It helps us to figure out when to perform the rehashing function for efficiency of operations.
Load Factor (α) = Number of elements inserted / Size of the hash table.
Why is Rehashing needed?
When the value of load factor crosses a threshold(0.7), we need to rehash the hash table to avoid collision.
- Create a new or larger hash table.
- Compute the hash indices again for all the existing keys using a new hash function or updated table size.
- Reinsert all the keys into the new table to reduce collision.
For Example:
- Size of hash Table: 5
| Index | Stored Keys |
| 0 | 5 |
| 1 | 12 |
| 2 | 15 |
| 3 | 22 |
| 4 | Empty |
Now, we will compute Load Factor with the previous formula.
Load Factor (α) = Number of elements inserted / Size of the hash table.
Load factor = 4/5 = 0.8 and it reaches the threshold, which is time to rehash the Table.
- Rehashing
- We will resize the table and create a new hash table(Double the previous size)
- Updated hash function: hash = key % 10
- Re-insert elements
| Key | New Index(key%10) |
| 5 | 5 |
| 12 | 2 |
| 15 | 5 (collision) |
| 22 | 2 (collision) |
Now, we noticed some of the collisions here, which we can handle using collision techniques.
Final Hash Table after using chaining will be as follows:
| Index | Stored Key(Linked List) |
| 0 | Empty |
| 1 | Empty |
| 2 | 12 à 22 |
| 3 | Empty |
| 4 | Empty |
| 5 | 5 à 15 |
| 6 | Empty |
| 7 | Empty |
| 8 | Empty |
| 9 | Empty |
This shows, key (12&22) and (5&15) are both stored in a linked list at the index 2 and 5 respectively.
Hashing is a fundamental and powerful concept in the journey of learning data structure. If you also want to master efficient coding and placements-level DSA, you can join our expert-led DSA course offline in Delhi, and online data structure algorithm course. You will gain hands-on experience with real-world problems, and industry-ready concepts to boost your career.